Luftlesen verrät Präsenz
Sensorik
Informationen über die Raumbelegung respektive die Präsenz sind wertvoll, um die Energieeffizienz, den Raumkomfort, die Raumluftqualität, die Funktionalität, die Sicherheit und schliesslich die Wirtschaftlichkeit von Gebäuden zu verbessern. Dabei gibt es einerseits verschiedene Kategorien der Präsenzschätzung und andererseits unterschiedliche Sensoren zu ihrer Ermittlung.

Die Präsenzschätzung ist ein nützliches Hilfsmittel, um die Energieeffizienz, den Raumkomfort, die Raumluftqualität und weitere Aspekte eines Gebäudes zu verbessern. Es gibt verschiedene Kategorien der Präsenzschätzung:
- Präsenz: Anwesenheit von Personen
- Präsenzzählung: Anzahl Personen
- Präsenzlokalisierung: Positionen anwesender Personen
- Präsenzidentität: Identität anwesender Personen
Dieser Beitrag befasst sich hauptsächlich mit den ersten zwei Punkten, denn sie sind für Effizienz- und Komfortsteigerungen am relevantesten.
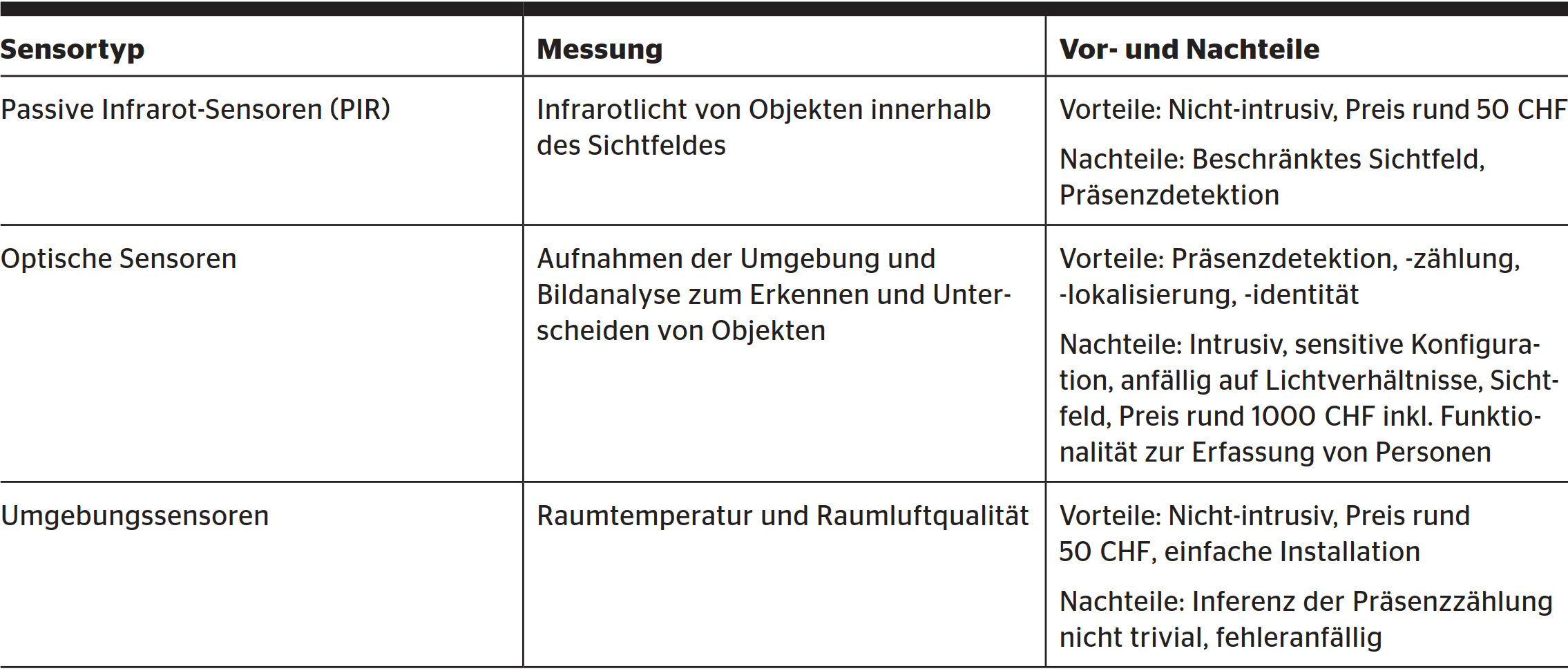
Zur automatischen Erfassung der Präsenz werden typischerweise Bewegungsmelder oder Präsenzmelder benutzt, am häufigsten passive Infrarotsensoren (PIR). Zum Einsatz kommen auch optische Sensoren für die Präsenzschätzung. Neben diesen direkten Messmethoden kann eine Präsenzschätzung auch indirekt durchgeführt werden, beispielsweise über Daten von Stromzählern, WLAN-Nutzungsdaten oder Raumtemperatur- und Raumluftqualitätssensoren wie CO2-Sensoren. Solche Sensoren können unterschiedliche Präsenzinformationen messen und haben ihre spezifischen Vorteile und Einschränkungen (Tabelle 1).
Eine komplizierte Beziehung
Eine interessante, kosteneffiziente und nicht intrusive Möglichkeit zur Inferenz der Präsenz und Präsenzzählung bildet die Auswertung der Raumlufttemperatur und -qualität, insbesondere der CO2-Konzentration. Sie erlauben Rückschlüsse auf die Präsenz und Präsenzzählung. Steigt beispielsweise die Anzahl der Anwesenden, so nimmt in der Regel die CO2-Konzentration zu. Der exakte Zusammenhang zwischen Präsenz, Anzahl anwesender Personen und CO2-Konzentration ist nicht trivial, sondern hochgradig nichtlinear und von vielen Faktoren abhängig.
Es gibt mathematische Ansätze, z. B. basierend auf der physikalischen Massenbilanzgleichung, die Rückschlüsse auf Präsenz und Anzahl Anwesender zulassen. Dieses physikalische Modell funktioniert für spezifisch modellierte Räume, die den initialen Annahmen entsprechen und bei denen die Modellparameter anhand ausreichender Daten genügend gut geschätzt werden können, beispielsweise ein geschlossener Raum mit den CO2-Quellen und CO2-Senken im Gleichgewicht. Dynamische Räume, also Räume, deren Zustand sich verändert, beispielsweise durch offene Türen, Fenster, wechselnde Aktivitäten oder interagierende Anwesende, führen zu komplexen und oft unbekannten Variablen. Sie lassen sich somit mathematisch nur schwer oder überhaupt nicht beschreiben.
Beziehungsanalyse mittels Machine Learning
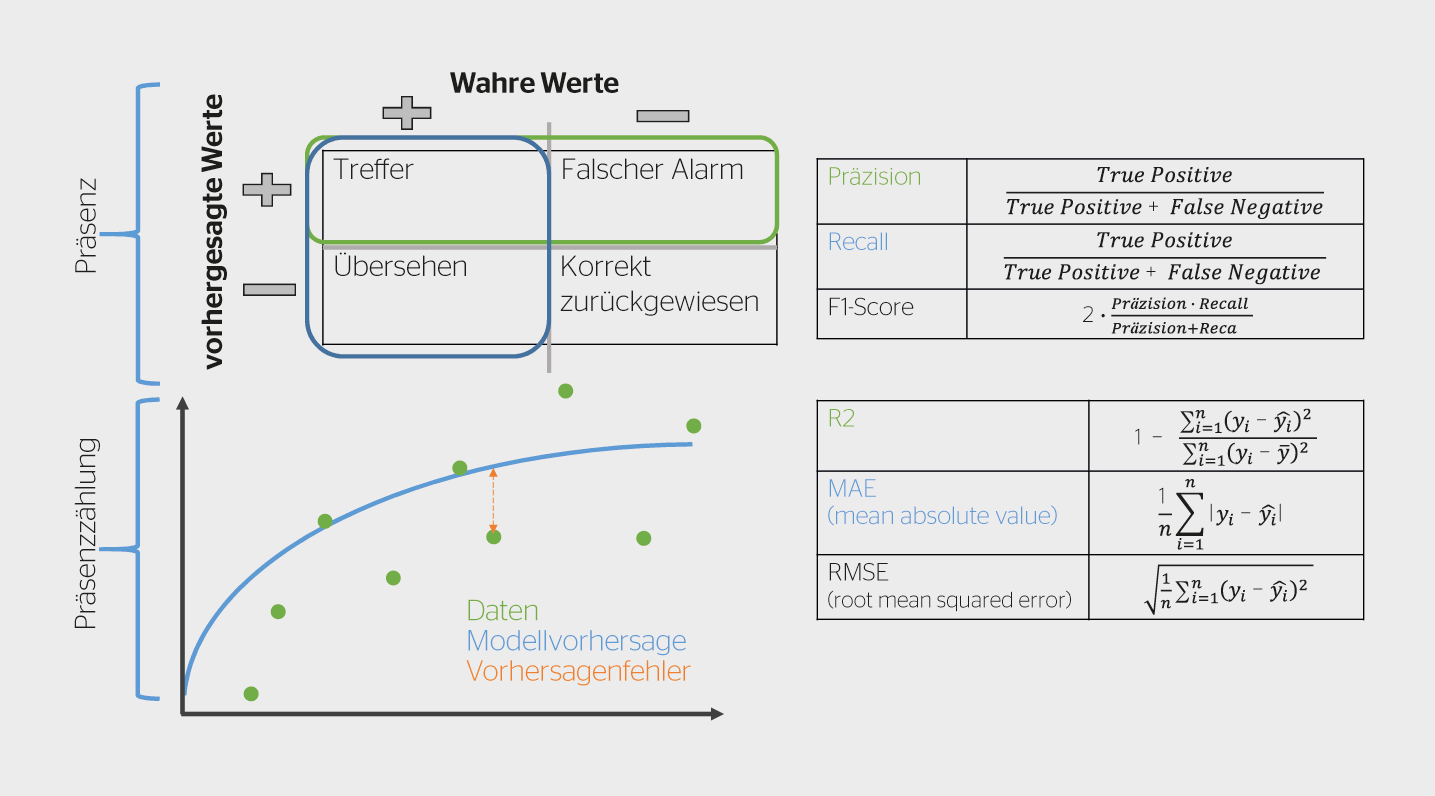
Zur Identifizierung komplexer und unbekannter Variablen wird oft auf Ansätze des Machine Learning, ML, zurückgegriffen. ML zeichnet sich dadurch aus, dass es anhand vorgegebener Lernalgorithmen und Daten Modelle generieren kann, die Zusammenhänge und Wechselwirkungen identifiziert, die ansonsten nur schwer zugänglich wären. ML leidet unter mangelnder Verallgemeinerung, was im konkreten Fall bedeutet, dass ein auf einen bestimmten Raum und dessen Sensorik angepasstes ML-Modell nicht auf andere Räume, die andere Charakteristiken und Sensorik aufweisen, übertragen werden kann. Die Probleme der reinen physikalischen Formulierung und des ML-Modelles lassen sich reduzieren, indem sie zu einem hybriden Modell kombiniert werden, z.B. mittels eines Stacking-Ansatzes [3]. Dieser Ansatz geht davon aus, dass sich gewisse Situationen besser durch ein physikalisches Modell beschreiben lassen und andere durch ein ML-Modell, wobei das hybride Modell durch die weiteren Daten diese Situationen lernt und entsprechend gewichtet. Der Ansatz ist interessant, da die Implementierung nur unwesentlich aufwendiger ist als die des reinen ML-Modells. Beim ML-Modell und dem hybriden Modell kommt der XGBoost-Algorithmus zum Einsatz [1]. Die Modelle werden mittels Recall und F1-Score resp. R2, MAE und RMSE evaluiert (Bild 1).
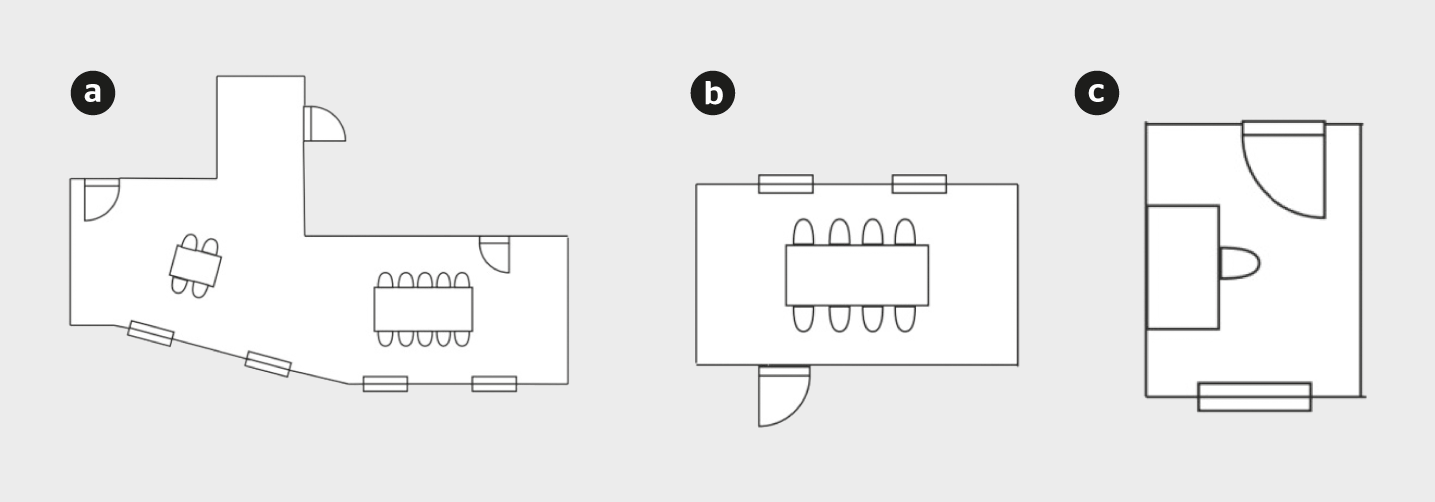
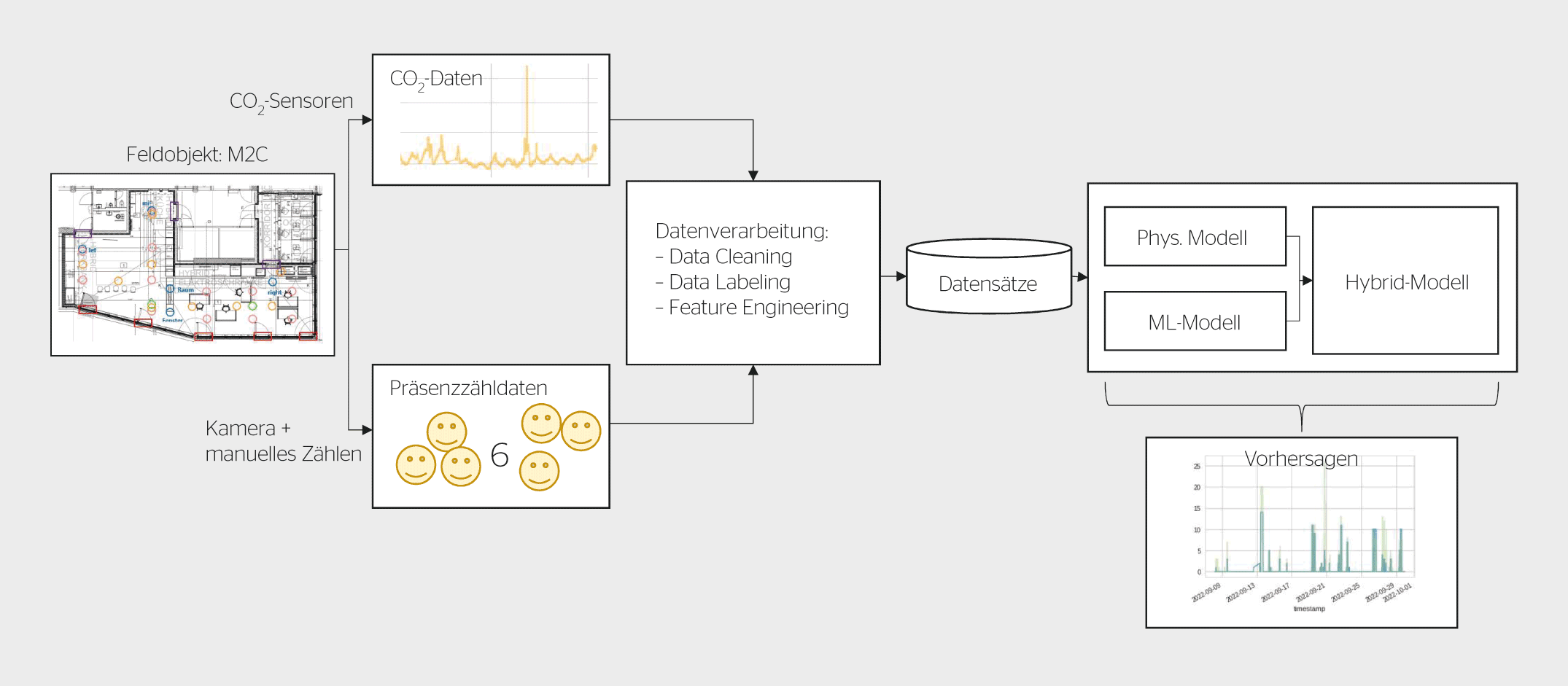
Das Ziel der vorliegenden Untersuchung, an der sich als Forschungspartner Oxygen at Work beteiligte, ist es, eine theoretische Vorstellung davon zu bekommen, wie gut sich mit Informationen zur CO2-Konzentration auf die Präsenz- und Präsenzzählung mit den drei Modellen schliessen lässt und ob sie sich für Anwendungsfälle zur Bestimmung der Präsenz in der Praxis eignen. Dazu werden folgende Kriterien definiert: Die Genauigkeit zur Evaluation von Präsenz und Präsenzzählung sowie der Implementierungsaufwand, der sich aus der Adaptierbarkeit und dem initialen Erstellungsaufwand für einen neuen Raum ergibt. Die Datensätze dreier Räume des Nest, dem modularen Forschungs- und Innovationsgebäude der Empa und der Eawag (Bild 2), vom Zeitraum Juli bis Oktober 2022 werden genutzt.
Die erste Iteration des ML-Modelles, kurz erstes Modell, definiert die Referenz und wird mit dem rohen Datensatz aus CO2-Konzentrationen und einer Kaskade an vergangenen CO2-Konzentrationen gefüttert. Die Genauigkeit der Prognose für die Präsenzzählung liegt für RMSE, MAE und R2 bei: 3,2, 1,2 und 0,22.
Feature Engineering berücksichtigt CO₂-Muster.
Es zeigt sich, dass die CO2-Konzentration alleine zur Inferenz der Präsenz nicht genügt, da dem ML-Modell nur eine Information mitgegeben wird, nämlich, wie sich eine Sequenz von CO2-Konzentrationen mit der aktuellen Anzahl der Anwesenden verhält. Weitere Informationen können durch den Vorgang des Feature Engineerings hinzugefügt werden. Beim Feature Engineering liegt der Fokus auf der Aufschlüsselung der CO2-Charakteristik: Aus den Zeitreihen der CO2-Konzentrationen lassen sich bestimmte, wiederkehrende Muster herauslesen, die durch ihren Anstieg, Plateaus, des CO2-Konzentrationsabfalles und deren absoluter Höhe charakterisiert werden können (Bild 3).
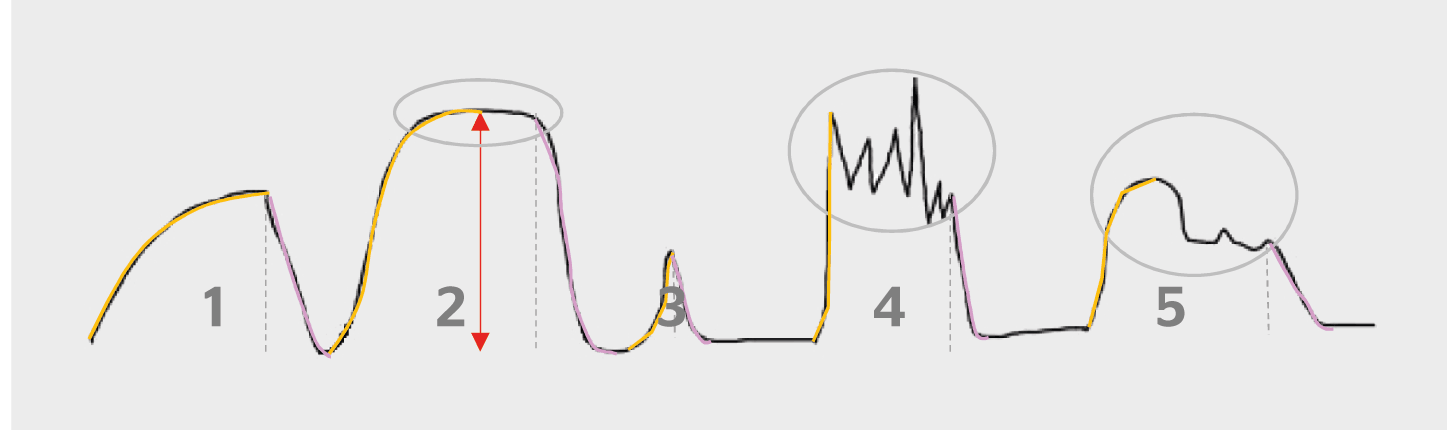
Die Informationen der verschiedenen CO2-Muster werden durch die Extraktion der Differenz erster Ordnung, abschnittsweise Gliederung in Bereiche vergleichbarer Statistik und Bestimmung der Standardabweichung und der mittleren absoluten Abweichung, linearer Trend und Hypothesentest der Stationarität, der Klassifizierung des CO2-Abfalls formalisiert. Das sogenannte «prior likely present»-Feature, das die Genauigkeit der Vorhersage stark erhöht, wird detailliert in Bild 4 vorgestellt.
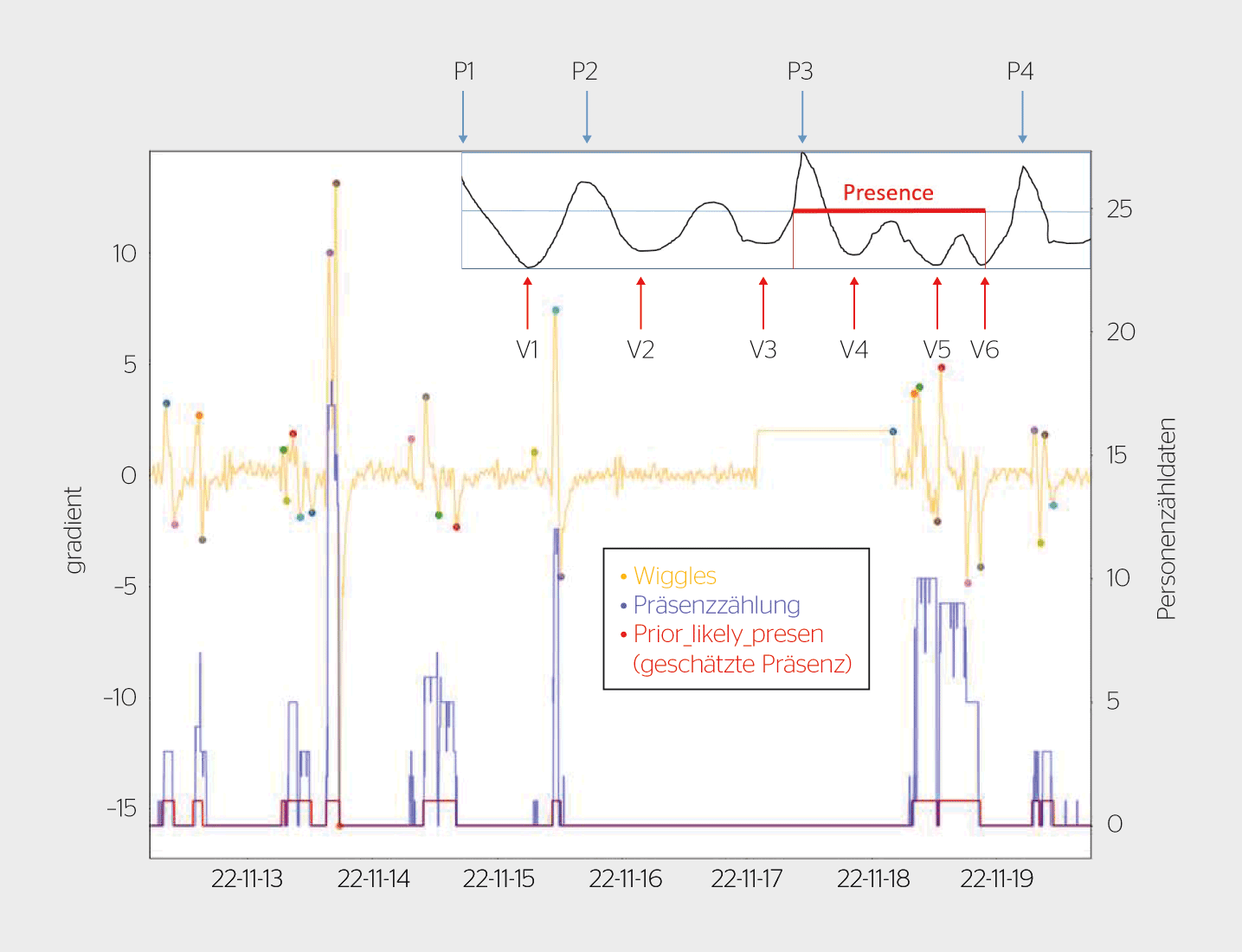
Die Modellvorhersagen des ersten Modells sind deutlich besser, wenn PIR-Präsenzdaten hinzugefügt werden. Da diese in einer realen Anwendung nicht zur Verfügung stehen würden, sind diese mittels Feature Engineering mit dem «Prior likely present» aus den Daten abgeleitet (Bild 4). Durch die Differenz erster Ordnung und Filterung ergeben sich Wiggles (gelb). Es fällt auf, dass diese Wiggles vornehmlich bei Präsenz auftreten. Sie erlauben es, in einem weiteren Schritt die Präsenz regelbasiert zu bestimmen. Die Präsenz ist hier der rote Bereich zwischen zwei deutlichen Maxima der Wiggles und verbindet den Start, mit dem letzten Minimum, vor dem nächsten grossen Maximum. Die Hinzunahme des «Prior likely present» ergibt einen F1-Score beim Vorhersagen der Präsenz von 0,69, wobei die PIR-Sensoren einen kombinierten Wert von 0,92 haben.
Klare Verbesserung mit Feature Engineering
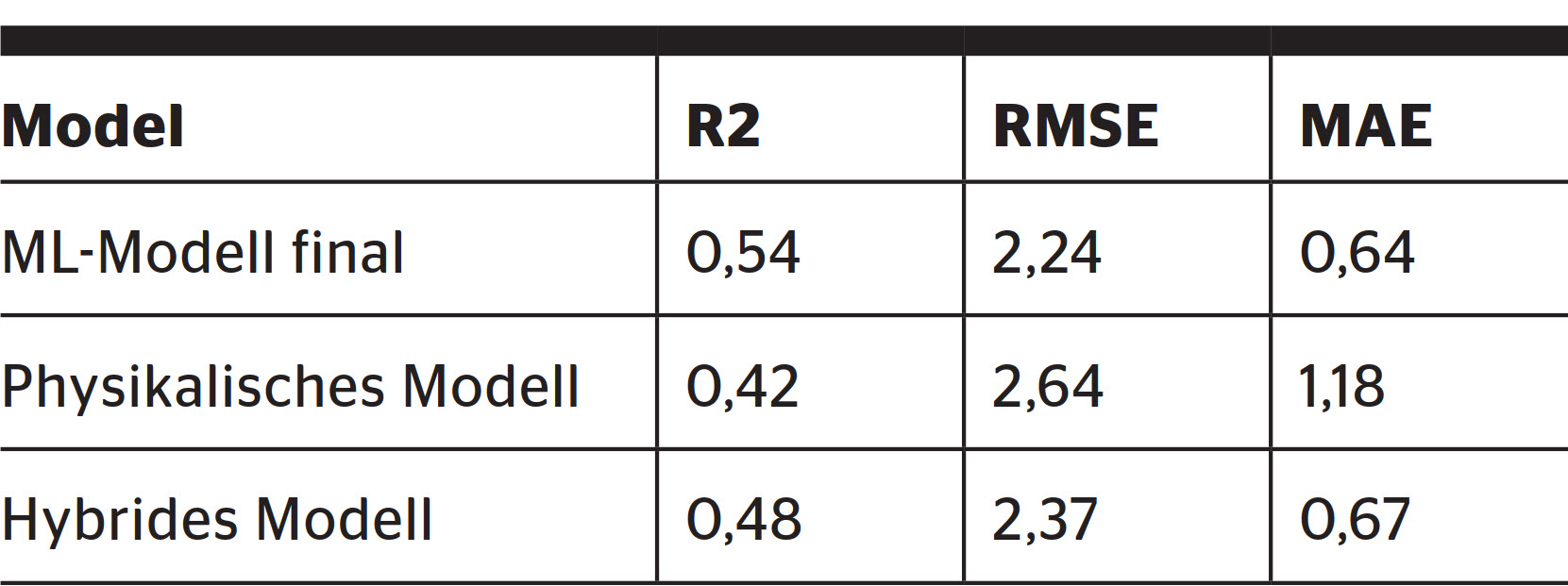
Im direkten Vergleich der Vorhersagen zur Präsenz zwischen ML-Ansatz und physikalischem Modell zeigt sich ein deutlicher Unterschied zwischen Präzision, Recall und F1-Score: 0,77, 0,75 und 0,76 vs. 0,29, 0,83 und 0,43, vgl. mit Literaturwerten für vergleichbares Setting F1-Score: 0,73 [2]. Dies ist zugleich die symptomatische Schwäche des physikalischen Modells. Das Modell reagiert sensitiv auf erhöhte CO2-Konzentrationen und bewertet einen Grossteil der beobachteten CO2-Konzentrationszunahmen als Präsenz. Dies führt auch zu den schlechteren Werten bei der Präsenzzählung im Vergleich zum R2-Score des ML-Ansatzes: 0,54 im Vergleich 0,42. Das bedeutet, dass 46 resp. 58 % der Personenzählvarianz durch die berücksichtigten Faktoren unerklärt bleiben und somit beide Ansätze nur einen mässigen Anteil der Varianz der abhängigen Variable erklären können. Die Gründe lassen sich aus Bild 5 ableiten. Dort wurde die Vorhersageverteilung aufgetragen, X-Achse ist die korrekte Präsenzzählung, Y-Achse ist die Modellvorhersage und am oberen Rand kann die Anzahl Stichproben einer Präsenzzählung abgelesen werden. Bei einer perfekten Übereinstimmung würde sich eine Gerade von links unten nach rechts oben ergeben. Aber bei den Vorhersagen tritt eine grosse Streuung ein und die Vorhersagegenauigkeit nimmt mit zunehmender Personenanzahl ab.
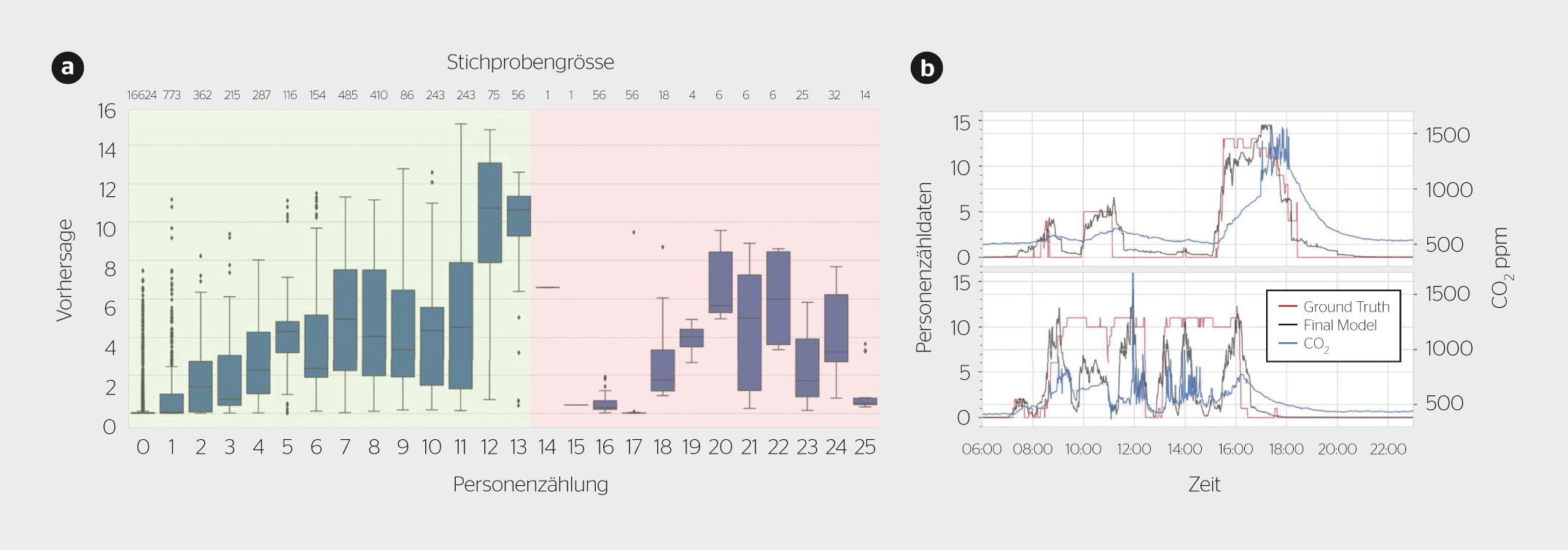
Das Diagramm lässt sich in zwei Bereiche, grün und rot, einteilen. Die Bereiche unterscheiden sich dabei in mehreren Punkten: Im grünen Bereich wird ein R2 zwischen Vorhersage und wahren Präsenzzähldaten von 0,57 erreicht; im roten Bereich ergibt sich ein negativer R2. Die Erklärung: Es liegen nur sehr wenige Samples für Präsenzzähldaten [gt] 13 vor. Zudem konnte bei grösserer Personenanzahl eine Zunahme der Aktivitäten beobachtet werden, insbesondere das Öffnen der Fenster und Türen, das sich stark auf die CO2-Konzentration auswirkt. Diesem Umstand wird mit keinem Feature Rechnung getragen. Wird die Information bezüglich dem Raumzustand hinzugefügt (offen oder geschlossen), so steigt R2 auf über 0,63 im Vergleich zu 0,54. Ignoriert man auch die Personenanzahl [gt] 13, steigt der R2-Wert auf 0,65. Das finale ML-Modell liefert im Allgemeinen gute Werte zur Vorhersage der Präsenz und Präsenzzählung, das physikalische Modell liefert hingegen nur mässige Werte.
Die Leistung des hybriden Modells (Bild 6) liegt leicht unter dem Niveau des reinen ML-Modells, weil die Vorhersagen des physikalischen Modells relativ hoch gewichtet werden. Somit erbt das hybride Modell auch dessen Schwächen bezüglich der Präsenzvorhersage. In den anderen beiden Testfällen, Sprint und Sizi, erzielte das hybride Modell wegen dem Stacking bessere Werte als das ML-Modell. Insgesamt zeigt sich, dass das hybride Modell stark vom ML-Modell abhängig ist. Wegen des erhöhten Implementierungsaufwands und hoher Ähnlichkeit mit ML wird in der weiteren Diskussion auf das ML-Modell und das physikalische Modell fokussiert (Tabelle 2):
Der initiale Implementierungsaufwand für das gut automatisierbare und skalierbare ML-Modell ist relativ gering: Neue Informationen können einfach mittels Feature Engineering hinzugefügt werden. Die initiale Erstellung des physikalischen Modells kann hingegen nur bedingt automatisiert werden (Raumvolumen oder Parameterschätzung). Beim physikalischen Modell können zudem neue Features nicht direkt integriert werden. Das finale ML-Modell hat Schwächen bei der Adaptierbarkeit und kann wie erwartet nicht auf ungesehene Objekte angewendet werden, denn es braucht gelabelte Daten, die teuer sind. Die Adaptierbarkeit des physikalischen Modells ist gut, solange die zugrunde liegenden Annahmen gültig bleiben. Die Einfachheit der Umsetzung hängt von der Verfügbarkeit und Güte der Schätzung der Eingangsparameter, wie Raumgrösse, Geschlechteranteil und Lüftungspraktiken ab, wobei natürlich belüftete Räume die kritischsten Szenarien darstellen.
Leistung der Modelle überzeugt, aber …
Am Ende liegt die Erkenntnis vor, dass das ML-Modell durch die Abhängigkeit von gelabelten Daten und mangelnder Adaptierbarkeit für den Einsatz zur Überwachung der Raumluftqualität nur beschränkt, unter hohen Kosten, genutzt werden kann. Die Leistungsvorteile überwiegen die Kosten nicht, weshalb das physikalische Modell hinsichtlich Performanz und Kosten zu bevorzugen ist. Letzteres zeigt insbesondere in Situationen, in denen die Lüftungspraktiken und Eckwerte des Raumes bekannt sind, zufriedenstellende Werte, und lässt sich auf alle Räumlichkeiten, für die das zutrifft, anwenden.
In zukünftigen Arbeiten wird der Fokus auf das ML-Modell gelegt. Insbesondere die Adaptierbarkeit und Möglichkeiten zur Evaluation des Raumzustands versprechen einiges, um neben einer deutlichen Performanzsteigerung auch einen breit gefächerten Einsatz zu ermöglichen.
Das könnte Sie auch interessieren

