Mit der Digitalisierung dekarbonisieren
Einsatz von dezentraler KI
Die Integration von volatilen erneuerbaren Energien in Verteilnetzen erschwert deren zuverlässigen Betrieb. Zwar können mit Smart Metern die Verbrauchs- und Produktionsdaten zur Betriebsoptimierung des Stromnetzes verwendet werden, jedoch limitieren Datenschutzbestimmungen den Einsatz der Endverbraucherdaten. Ein KI-Tool soll da Abhilfe schaffen.

Auch in der Schweiz machen Regulierungen die Installation von Smart Metern allgegenwärtig. Das revidierte Energiegesetz, das seit 1. Januar 2018 in Kraft ist, zielt auf eine 80%ige Abdeckung der Endverbraucher bis 2027. Digitale Instrumente ermöglichen es, diese vielen Datenquellen effizient zu nutzen, um die Dekarbonisierung voranzutreiben. Dadurch kann die Leistungsfähigkeit von Stromnetzen verbessert und erneuerbare Energien können effektiver in Verteilnetzen integriert werden. EVUs und Dienstleister untersuchen Möglichkeiten, um die künstliche Intelligenz (KI) und andere moderne Data-Science- Techniken basierend auf Smart-Meter- Daten zu nutzen und zusätzliche Vorteile für Geschäfts- und Endkunden zu schaffen. Die Herausforderungen beim Zugriff, der Aggregation und der Analyse von Zählerdaten limitieren die Einführung dieser Technologien jedoch stark. Die Zentralisierung von Smart- Meter-Daten für die Analyse führt zu Schwachstellen in den Bereichen Datensicherheit und Datenschutz, und Datenschutzbestimmungen verhindern in der Regel die Verwendung der Daten für andere Zwecke als die Abrechnung. Das Ziel des Projekts Knowledge (Eigenschreibweise: KnowlEDGE) ist es, nach Möglichkeiten zu suchen, wie Smart-Meter-Daten genutzt werden können, wenn sie bereits am Erfassungsort verarbeitet werden. Zusätzlich zu den Kernzielen wird das Projekt indirekt die Realisierung des vom BFE vorgeschlagenen National Datahub unterstützen, indem es das Potenzial von dezentralen Datenverarbeitungsansätzen aufzeigt.
Datenschutz durch dezentrale künstliche Intelligenz
Im Knowledge-Projekt werden Alternativen zur zentralen Datenaggregation entwickelt, welche die Nutzung von KI-Ansätzen für EVUs erheblich vereinfachen sollen. Insbesondere werden dezentrale Ansätze entwickelt, die auf Anwendungsfälle von Verteilnetzbetreibern (VNB) zugeschnitten sind. Dazu gehören:
- Profilerstellung / Vorhersage der Netzbelastung in Nieder- und Mittelspannungsnetzen, die bei Lastmanagement, Überlastung und Drosselung helfen sollen;
- Erkennung und Vorhersage von Netzwerkanomalien und Versorgungsqualitätsmängeln, um netzwerkbasierte Korrekturmassnahmen zu ergreifen; und
- Unterstützung von lokalen Dienstleistungen zur Verbesserung des Netzbetriebs.
Ein Schwerpunkt des Projekts ist die Auswertung des Mehrwerts einer verteilten (federated) Analysestrategie zur Wertschöpfung von industriellen, gewerblichen und privaten Smart-Meter-Daten (Bild 1).
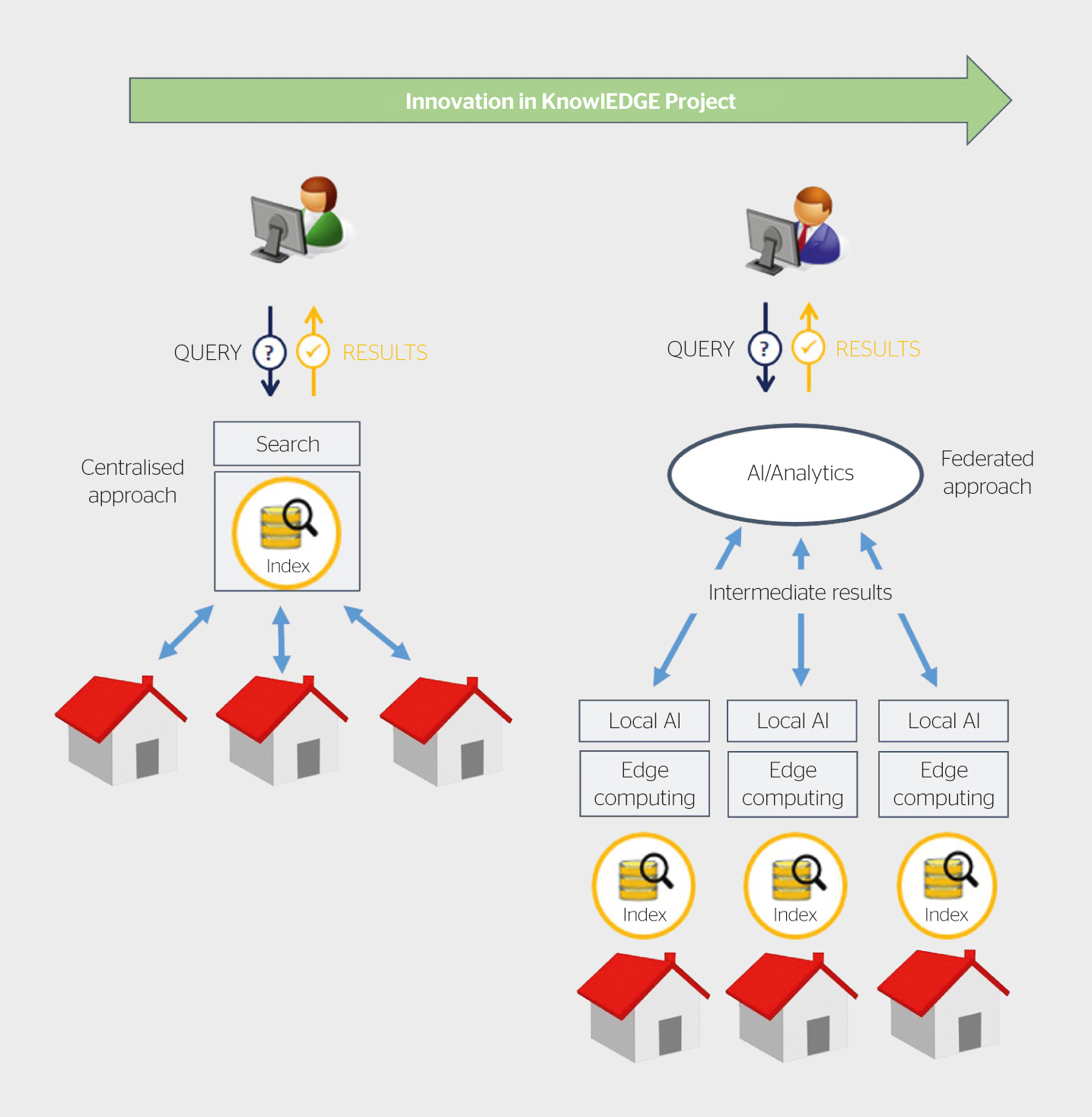
Verteilte Engpassberechnungen und private Lastprognosen
Eine Simulationsumgebung wurde im Projekt entwickelt, mit der die Netzwerkbelastung für das Verteilnetz auf Basis von Docker-Containern und dem MQTT-Protokoll (Message Queuing Telemetry Transport) verteilt berechnet werden kann. So kann die Netzwerkbelastung ohne Datenzentralisierung berechnet werden, wobei sich verschiedene Parameter wie die Leistungsfähigkeit des Kommunikationssystems verändern lassen. Man kann zudem mit Rechenanforderungen in verschiedenen Teilen des Netzwerks, insbesondere in Smart Metern, experimentieren.
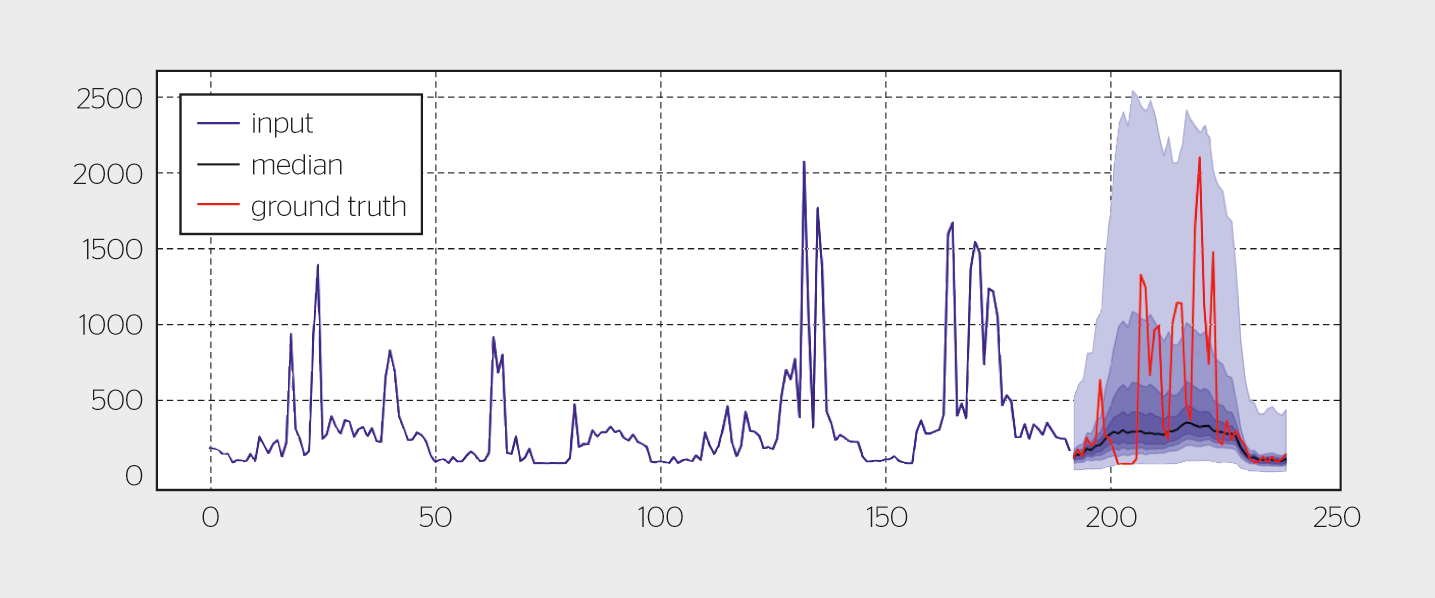
Mehrere maschinelle Lernmodelle für die Lastprognose wurden trainiert und getestet. Als Referenz für die dezentralen Methoden diente ein zentralisierter Ansatz mit unbeschränkten Rechenressourcen. Zusätzlich wurde ein Ansatz erarbeitet, mit dem die Machbarkeit der Ausführung von Prognosealgorithmen direkt auf Smart Metern untersucht werden konnte (Bild 2). Zum Projekt gehörte auch die Entwicklung von Strategien zur Modellpersonalisierung mit einem Ansatz namens Federated Learning.
Das Projekt ergab, dass die Leistungsmerkmale zentralisierter und dezentraler KI-Modelle ähnlich sind. Der Prozess des Trainings von Prognosemodellen auf Endgeräten wird immer noch untersucht. Es hat sich gezeigt, dass selbst in modernen Softwarebibliotheken wie TensorFlow Lite noch Anpassungen erforderlich sind, um KI-Modelle auf Endgeräten für die Lastprofilprognose zu verwenden.
Federated Learning verbessert Datenschutz
Federated Learning ist ein maschineller Lernansatz (ML), der es ermöglicht, das Lernen dezentral an dem Ort auszuführen, an dem die Daten generiert werden. Statt die Daten zentral zu verarbeiten, teilt der Ansatz den Trainingsprozess auf mehrere Knoten auf. Dies bietet zwei Hauptvorteile: Erstens schützt es die Privatsphäre inhärent, indem es den EVUs ermöglicht, nur selektiv Informationen zu zentralisieren; zweitens reduziert es das Volumen des Datenaustauschs für die Analyse.
EVUs sammeln Lastkurven meist in einer Master-Datenbank in einem «Head-End-System», das einen integralen Bestandteil moderner Zählerinfrastruktur bildet. In der Praxis führt dies zu Hindernissen, denn gesetzliche Bestimmungen stufen Lastkurven als sensible Daten ein und schützen diese in hohem Masse. Deshalb dürfen die Daten nur für Analysen zur Abrechnung verwendet werden. Eine besondere Erlaubnis der Endverbraucher kann den Anwendungsbereich der Daten erweitern, aber die Übertragungsrate limitiert die Effektivität eines zentralen Ansatzes erheblich. Typischerweise werden Lastkurven in 15-Minuten-Intervallen abgebildet und einmal täglich an das Head-End-System übertragen. Auf den Smart Metern können jedoch Daten mit einer viel höheren Auflösung generiert werden, ohne das Zählerdesign komplexer zu machen. Dies ermöglicht es, dezentral präzisere KI-Lernmodelle zu erstellen.
Diese beiden Limitierungen lassen sich mit Federated Learning gleichzeitig angehen, indem das Lernen des KI-Modells lokal stattfindet, wo die Daten generiert werden. Das EVU kann so seinen Datenschutzbestimmungen nachkommen und profitiert zugleich von einem geringeren Datenvolumen, das mit den Smart Metern ausgetauscht und zentral gespeichert werden muss.
Wie funktioniert dies in der Praxis? Ein Server initiiert eine Anfrage an ein Endgerät, um einen Trainingsprozess eines Modells zu starten, das entweder an das Endgerät übertragen wird oder dort bereits vorhanden ist. Nach Erhalt der Trainingsanweisung führt das Endgerät einen dezentralen Trainingsprozess für den lokalen Datensatz durch. Der Datensatz ist meist überschaubar, und das Modelltraining wird nur teilweise komplettiert, basierend auf einer begrenzten Anzahl von Iterationen. Nach der erforderlichen Anzahl von Trainingsiterationen wird das teilweise neu trainierte Modell von jedem Endgerät an den zentralen Server zurückgesendet, und der Server kombiniert die Modelle zu einem aktualisierten globalen Modell. Dieses wird dann an alle Endgeräte zurückgesendet, und der Vorgang kann wiederholt werden.
Durch diesen Prozess trägt jedes Endgerät zum Training bei, ohne sensible Daten zu übertragen. Da nur ein aktualisiertes Modell zurückgesendet wird, wird die zwischen Server und Endgerät ausgetauschte Datenmenge drastisch reduziert.
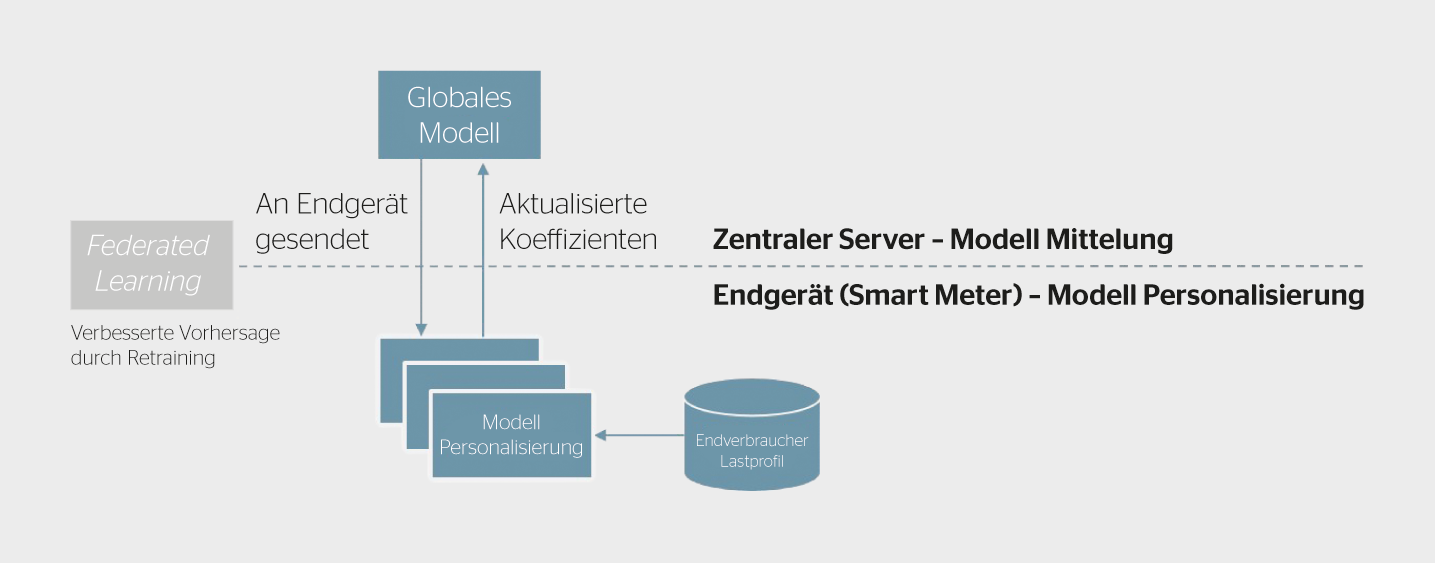
Im Projekt wurden verschiedene Federated Learning Frameworks untersucht, insbesondere, wie diese Frameworks auf Endgeräten mit geringer Rechenleistung und kleinem Speicher implementiert werden können (Bild 3). Federated Learning erfordert, dass die Trainingsalgorithmen auf Endgeräten ausgeführt werden; dies führt zu Kompromissen zwischen Datenaggregation, Modellleistung und Hardwarenutzung. Es zeigte sich, dass heutige Smart Meter für Privathaushalte nur bedingt Modelltrainings dezentral durchführen können. Eine neue Generation von Smart Metern mit Standardbetriebssystemen wie Linux und ML-fähigen Prozessoren (beispielsweise ARM-Cortex M7) ermöglicht jedoch, Federated Learning auf Smart Metern zu implementieren und den Anforderungen der Anwendungsfälle im Projekt gerecht zu werden. Der Reifegrad von Federated Learning Frameworks stellt eine zusätzliche Herausforderung für die Implementierung von Federated Learning für Anwendungsfälle von EVUs dar. Zurzeit werden mehrere Optionen geprüft, wobei das Flower-Framework die vielversprechendste Option zu sein scheint.
Zentrale Rolle des Smart Meters
Die Möglichkeiten von Smart Metern machen diese zu einem wichtigen Enabler für die Bereitstellung von dezentralen ML-Modellen. Basierend auf den Kosten und individuellen Anforderungen von EVUs variieren die Rechenressourcen von Smart Metern stark. Technisch ist es zwar möglich, ML-Modelle direkt in Smart-Meter- Firmware zu integrieren, jedoch ist dies wegen kommerzieller und geschäftlicher Einschränkungen aufwendig. Wenn die Vorteile von «Edge Computing» von den EVUs erkannt werden und sie dies als Mindestanforderung für Smart Meter fordern, ist die Situation entschärft. Damit ML-Applikationen von Drittanbietern entwickelt und genutzt werden können, müssen Smart Meter eine bekannte Entwicklungsumgebung bereitstellen. Was bei Industriezählern allmählich üblich ist, gilt bei Haushaltszählern noch als Zukunftsperspektive. Im Projekt wird mit dem Landis+Gyr S650 Smart Grid Terminal und der E65C Remote Terminal Unit in Feldversuchen sowie mit dem E360 Residential Meter im Labor experimentiert. Das Ziel von Feldversuchen ist, die Vorhersage von Lastprofilen und Netzwerkbelastungsberechnungen auf Smart Metern sowie die Datenübertragung zwischen Smart Metern aufzuzeigen. Dort, wo die Rechenkapazität von Haushaltszählern begrenzt ist, werden Alternativen gesucht, wo die Berechnungen ausgeführt werden können, bevor die Daten aggregiert werden, beispielsweise in Datenkonzentratoren.
Im Projekt wird mit Datenclustering und Modellpersonalisierung experimentiert, um den potenziellen Mehrwert der Modellmittelung innerhalb des Federated Learning Frameworks zu demonstrieren. Ein Grossteil der bisherigen Analysen basiert auf Open-Source-Datensätzen wie z. B. den Smart-Meter-Messwerten, die im Rahmen des Low-Carbon-London-Projekts öffentlich zugänglich gemacht wurden. Im Feldversuch mit Projektpartner Romande Energie soll aufgezeigt werden, wie Federated Learning genutzt werden kann, um die generischen Modelle auf die konkreten Gegebenheiten im Testfeld zu übertragen. Zusätzlich wird untersucht, wie individuelles Endverbraucherverhalten in Prognosemodellen mit Personalisierung genauer repräsentiert werden kann, wenn Federated Learning eingesetzt wird.
Gleichzeitig werden die Untersuchungen im Bereich des Federated Learning auf Geräte mit eingeschränkten Ressourcen erweitert. Als Ausgangspunkt werden Geräte gewählt, die sich für eine schnelle Prototypentwicklung eignen, wie der Raspberry Pi. Schliesslich wird aber Hardware eingesetzt, die repräsentativer für moderne Smart Meter für Privathaushalte und Industrie ist, damit die Vorteile des Projektansatzes im Testfeld von Romande Energie in Rolle demonstriert werden können.
Datenschutz durch Design
Die im Projekt entwickelte Simulationsumgebung garantiert den Datenschutz durch ihr Design. Unabhängig von den Anforderungen im Testfeld geht es darum, einen Ansatz zu entwickeln, der auf unterschiedlichen Geräten eingesetzt werden kann. Die Docker-basierte Umgebung ist ein Kernbestandteil der Lösung. Es wird weiterhin am Konzept der containerisierten Software für intelligente Zähler gearbeitet, denn die Containerisierung, kombiniert mit Federated Learning und geeigneten kryptografischen Techniken, scheint das Potenzial zu haben, diverse potenzielle Anwendungen und Dienste für Prosumer zu erschliessen, ohne die Privatsphäre oder Sicherheit zu beeinträchtigen.
Ein zentraler Teil des Projekts ist die kryptografische und sichere containerisierte Umgebung des Projektpartners VIA, einem Anbieter von KI- und Datenschutzsoftware. Ihre Trusted Analytics Chain Plattform (TAC) bietet Software zur Verwaltung des Zugriffs auf verteilte Datensätze und stellt sicher, dass rechtliche und Cybersicherheitsanforderungen erfüllt werden können. Die Kerncontainer der Plattform wurden kürzlich vom US-Verteidigungsministerium für das höchste Mass an Cybersicherheit akkreditiert. TAC wird bei Romande Energie während der Feldversuche eingesetzt.
Übertragbare Ergebnisse
Fortschrittliche Analysemethoden, die auf dezentraler Datenverarbeitung basieren, haben das Potenzial, die Ziele der Schweizer Energiestrategie 2050 zu unterstützen, indem sie EVUs ermöglichen, Stromnetze besser zu überwachen und zu betreiben. Dies wiederum hilft bei der Integration erneuerbarer Energien und der Dekarbonisierung.
Im Knowledge-Projekt wurde die Machbarkeit und der Vorteil der Anwendung von verteilten Ansätzen für die Berechnung der Netzbelastung und die Überwachung der Versorgungsqualität untersucht. Bisherige Analysen haben potenzielle Vorteile von dezentralen KI-Systemen für die Netzbelastungsberechnung gezeigt. Obwohl die bestehende Smart-Meter-Infrastruktur nur über eine begrenzte Rechenleistung verfügt, sind die Autoren der Ansicht, dass die Lösung mit industriellen Zählern und moderner Messinfrastruktur in Verteilnetze integriert werden kann.
Der im Knowledge-Projekt entwickelte Ansatz bietet viele Anwendungen im Bereich der Integration erneuerbarer Energien, E-Mobilität, Verbraucherengagement, Lastdisaggregation – und kann somit massgebend zur Dekarbonisierung beitragen. Die Erkenntnisse können auch auf andere Lösungen für den Datenzugriff und den Datenschutz im Energiesektor übertragen werden, wo eine Zentralisierung der Daten vermieden werden sollte.
Das Knowledge-Projekt läuft von 2019 bis 2022. Das Projekt wurde mit Hilfe des Smart-Meter-Herstellers Landis+Gyr, des Kryptografie- und Datenschutzunternehmens Via Science AG (VIA) und des EVUs Romande Energie SA initiiert und wird vom BFE gefördert.
Das könnte Sie auch interessieren

